This article introduces the optimization of deferred execution in version 0.2.0 from a technical perspective.


Python interactive analysis is widely popular in the field of data science. In environments such as Jupyter notebook and IPython, users can conveniently debug, visualize data, and quickly prototype their work.
We are well aware that the experience of using Xorbits in interactive environments is crucial for our users, and therefore, we want Xorbits to be stable and efficient, minimizing users’ waiting time. To achieve this goal, we have optimized the deferred execution strategy in interactive environments in version 0.2.0.
This article mainly introduces the optimizations made to deferred execution in version 0.2.0 from a technical perspective.
What is Deferred Execution
Most computation frameworks use either eager or lazy execution strategies. In eager execution mode, computation is triggered whenever the user makes an invocation, while in lazy execution mode, the user need to call a special method to let the computational framework know it is time to do the computation. Generally speaking, eager execution is more intuitive for users as it behaves like a single-machine software, while lazy execution often results in better performance since optimizations can be applied to user’s invocations.
Xorbits combines the advantages of both eager and lazy execution strategies, and we call it deferred execution. Xorbits automatically determines whether the computation should be triggered when an invocation happens. Therefore, Xorbits users can enjoy both the experience of single-machine software and the strong performance brought by optimization.
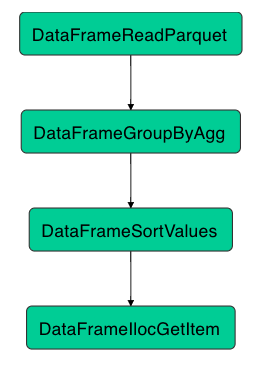
Taking the following code as an example, it reads all the trip records of New York taxis in 2021, groups them by pickup area, calculates the number of records for each group, and prints the top 10 areas with the most records:
import xorbits.pandas as pd
trips = pd.read_parquet('yellow_tripdata_2021')
gb_pu_location = trips.groupby(['PULocationID'], as_index=False).agg(count=('PULocationID', 'count'))
gb_pu_location.sort_values(by='count', ascending=False, inplace=True)
print(gb_pu_location.iloc[: 10])
As the user only cares about the final printed result, Xorbits defers execution until the print function is called. Then, a computation graph will be constructed and optimization rules will be applied. It can be seen that the final result only relates to the PULocationID column. Therefore, Xorbits will only read the single column, reducing the computation load greatly. For the common operation of sorting and taking the top n rows, Xorbits merges sort_values and iloc into one operator for better performance.
During the execution of the computation graph, as we only care about the final result, Xorbits will release the memory occupied by the results of intermediate steps. In other words, the results of the read_parquet, groupby, and sort_values will be released after the execution. In a non-interactive environment, this strategy maximizes the efficiency of memory usage and increases the maximum throughput of the system.
The Problem in Interactive Environments
However, in interactive environments, intermediate results may be repeatedly used. If intermediate results are released after each execution, we will need to recalculate them the next time they are used.
Let’s put the previous example in an interactive environment:
In [1]: import xorbits.pandas as pd
In [2]: trips = pd.read_parquet('yellow_tripdata_2021')
In [3]: gb_pu_location = trips.groupby(['PULocationID'], as_index=False).agg(count=('PULocationID', 'count'))
In [4]: gb_pu_location.sort_values(by='count', ascending=False, inplace=True)
In [5]: print(gb_pu_location.iloc[: 10])
Just like the previous example, Xorbits defers execution until the invocation of print. The calculation process stays the same, and the intermediate results such as trips will be released after the execution.
Now, if the user wants to view the IDs of the 10 areas with the least number of records, they can modify the code as follows:
In [6]: print(gb_pu_location.iloc[: -10])
Since the intermediate results have been freed, we have to re-execute the code from the very beginning. By comparing the computational graphs of In[5] and In[6], we can see that read_parquet and groupby are completely unnecessary (the sort_values operators are different due to Xorbits’ optimization).
| In[5] | In[6] |
|---|---|
 |
 |
Our Solution
In version 0.2.0, we solved the problem.
The core issue is to determine which intermediate results should be freed and which should be retained. We believe that the most intuitive solution for users is to retain intermediate results corresponding to variables in the user namespace. Here, the user namespace refers to the namespace under the Python Frame where the user can interactively program.
Therefore, we need to:
- Determine whether Xorbits is running in an interactive environment
- Collect the intermediate results in the user namespace
- Include the intermediate results as output nodes in the computation graphs.
Still taking the previous code as an example, let’s take a look at what the optimized computational graph looks like.
| In[5] | In[6] |
|---|---|
 |
 |
After the optimization, the computation graphs of In[5] and In[6] have both changed. For In[5], sort_values operation cannot be merged with iloc into one operator in order to retain the original results of sort_values. For In[6], since the result of sort_values is retained, it does not need to be recalculated. In our testing environment, the execution time of In[6] has been reduced by 75%.
For more details, please check out the discussion and implementation.
Conclusion
We hope that the optimization for interactive scenarios in Xorbits 0.2.0 can truly improve the user experience. There are more optimizations like this in Xorbits, and better user experience has always been our goal. We look forward to valuable feedbacks.
Finally, please follow us on Twitter and Slack to connect with the community!