We are excited to announce our new project, Xorbits, a scalable data science framework that aims to scale the entire Python data science world.


We are excited to announce our new project, Xorbits, a scalable data science framework that aims to scale the entire Python data science world.

Before delving into the details, I’d like to highlight some of the key features of Xorbits:
-
Xorbits is incredibly easy to get started, if you know how to use pandas , you would probably know how to use Xorbits. In addition to pandas API, Xorbits also supports numpy API, and will integrate more APIs in the future.
- Xorbits is lightening fast, and able to process terabytes of data with ease. According to our benchmark test, Xorbits is the fastest distributed data science framework compared to the most popular frameworks right now.
- Xorbits is super easy to deploy with official support for running on your laptop, existing cluster, Kubernetes, and the cloud.
Background: Python data science world
Python has become the most popular programming language
The increasing popularity of AI and data science has further propelled Python to the forefront as the most popular programming language.
According to the most representative programming language ranking websites, Tiobe Index and IEEE spectrum, until Jan 2023, Python is the top 1 programming language.

Tiobe Index

Top pgrogramming laguages from IEEE spectrum
Data analysis and machine learning are the top popular fields
According to Python developer survey of 2021 conducted by PSF and Jetbrains, data analysis and machine learning are already the top popular fields for Python usage.

Python developer survey of 2021
Numpy, Pandas etc are the top popular libraries for data science
According to Python developer survey of 2021 conducted by PSF and Jetbrains and stackoverflow 2022 developer survey , numpy, pandas etc are the top popular libraries.

Python developer survey of 2021
What we need to scale Python data science?
As more users flock to the Python data science world, several issues may arise, including:
- The current ecosystem may struggle to process large datasets. While libraries such as numpy and pandas are suitable and fast for working with data at the megabyte scale, when data grows to gigabytes or larger, users may encounter errors such as “out of memory.”
- Libraries like numpy and pandas lack scalability. Most operations in these libraries can only run on a single CPU, making it difficult to scale to multiple cores or clusters. Additionally, hardware such as GPUs that are commonly used for AI applications cannot be utilized to accelerate data science tasks.
Users can upgrade their machines. but since most operations in these libraries cannot utilize multiple cores, this may not be an effective solution. The only useful enhancement would be an increase in memory.

Given these limitations, users may require an alternative solution for scaling data science. In our view, the following key points should be taken into consideration.
Compatibility with the existing ecosystem
Libraries such as pandas and numpy have been widely adopted due to their user-friendliness and wealth of features. Any substantial modifications to their APIs would require users to make considerable changes to their existing code, which would be a significant burden for those who have many historical tasks that need to be scaled.
Data model consistency
The data model used by pandas is crucial for many operations. For example, data with a datetime index is organized in a time sequence, making it easy to perform time-series analytics. If the scaled version of pandas does not maintain this data model, users may get incorrect results when migrating from pandas to the scaled version.
Current frameworks
There are already a number of frameworks that attempt to address scalability issues.
Dask
Dask is a widely used, scalable data science framework that can be used to scale a variety of Python libraries, including numpy, pandas, and xgboost. However, it utilizes a lazy-evaluation approach, requiring users to manually call .compute() to trigger computation which can be inconvenient. Additionally, Dask dataframes do not fully follow the pandas data model and do not guarantee data sequence.
Modin
Modin is a scalable pandas framework that allows users to scale their pandas code by changing a single line of code.
Unlike dask, modin does not require users to call any function to trigger computation, it’s eagerly executed. This is great, but this means that there’s nearly no room for any optimization. We all know that SQL is sometimes efficient due to the reason that many optimization can be applied during the computation. If the code is completely eager, we’ll have no chance to insert intermediate optimization during the computation.
Additionally, Modin follows the pandas data model but it only supports the pandas API, so it cannot scale workloads that rely on other libraries.
Pandas API on Spark
Spark is a very popular and successful framework for large scale ETL. Pandas API on Spark is introduced in Spark 3.2, before that it’s called Koalas and initially it’s an individual project under the umbrella of Databricks.
As it is built on Spark, it inherits both the benefits and drawbacks of Spark. One benefit is that Spark is mature and has a wide range of tutorials and articles available. However, Spark is a big data framework developed in the Java ecosystem, and it’s relatively a heavy framework that requires specialized knowledge and people to run and maintain. Additionally, if the user’s code is incorrect, the error stack can be large and contain Java elements, which can be difficult for users to troubleshoot. In terms of data model, Spark does not guarantee data sequence, so operations such as shift and rolling using the pandas API on Spark are not scalable and fall back to a single node.
Other frameworks
There are many other frameworks like Vaex, polars etc, but they may not be as widely used or have more limited capabilities, such as running only on a single machine, so they will not be discussed further.
Why Xorbits?
The goals of Xorbits are straightforward, we want to address all the problems we have mentioned.
- Fully compatible APIs with existing data science libraries.
- Follow the data model of pandas.
- Extremely fast execution speed.
- Utilize hardwares like GPU.
- Simple deployment to clusters and cloud environments
A comparison of Xorbits with other frameworks is provided in a table.
| Dask | Modin | Pandas API on spark | Xorbits | |
|---|---|---|---|---|
| Compatible API | ❌ | ✅ | ✅ | ✅ |
| Pandas data model | ❌ | ✅ | ❌ | ✅ |
| GPU support | ❌* | ❌ | ❌ | ✅ |
| Numpy API | ✅ | ❌ | ❌ | ✅ |
| JVM independent | ✅ | ✅ | ❌ | ✅ |
* GPU support on Dask is supported by RAPIDS dask-cudf
To evaluate performance, we conducted benchmarks on TPC-H at scale factor 100 (~100 GB of data) and 1000 (~1TB of data). TPC-H is primarily designed for OLAP applications and only utilizes a small subset of pandas APIs, but it is a widely recognized benchmark and all frameworks being compared support the APIs used in TPC-H. This allows for a fair comparison. We will be adding more benchmarks in the future to take advantage of the full range of pandas APIs.
For the TPC-H SF 100 benchmark, the cluster consisted of an r6i.large instance as the supervisor and 5 r6i.4xlarge instances as workers.
TPC-H SF100: Xorbits vs. Dask

TPC-H SF100: Xorbits vs. Dask
The benchmark results showed that Xorbits was 7.3 times faster than Dask across all queries, Q21 was excluded as Dask ran out of memory.
TPC-H SF100: Xorbits vs. Pandas API on Spark

TPC-H SF100: Xorbits vs. Pandas API on Spark
The benchmark results showed that across all queries, Xorbits and Spark Pandas API had roughly similar performance, but Xorbits provided significantly better API compatibility. Spark Pandas API failed on queries Q1, Q4, Q7, Q21, and ran out of memory on Q20.
TPC-H SF100: Xorbits vs. Modin
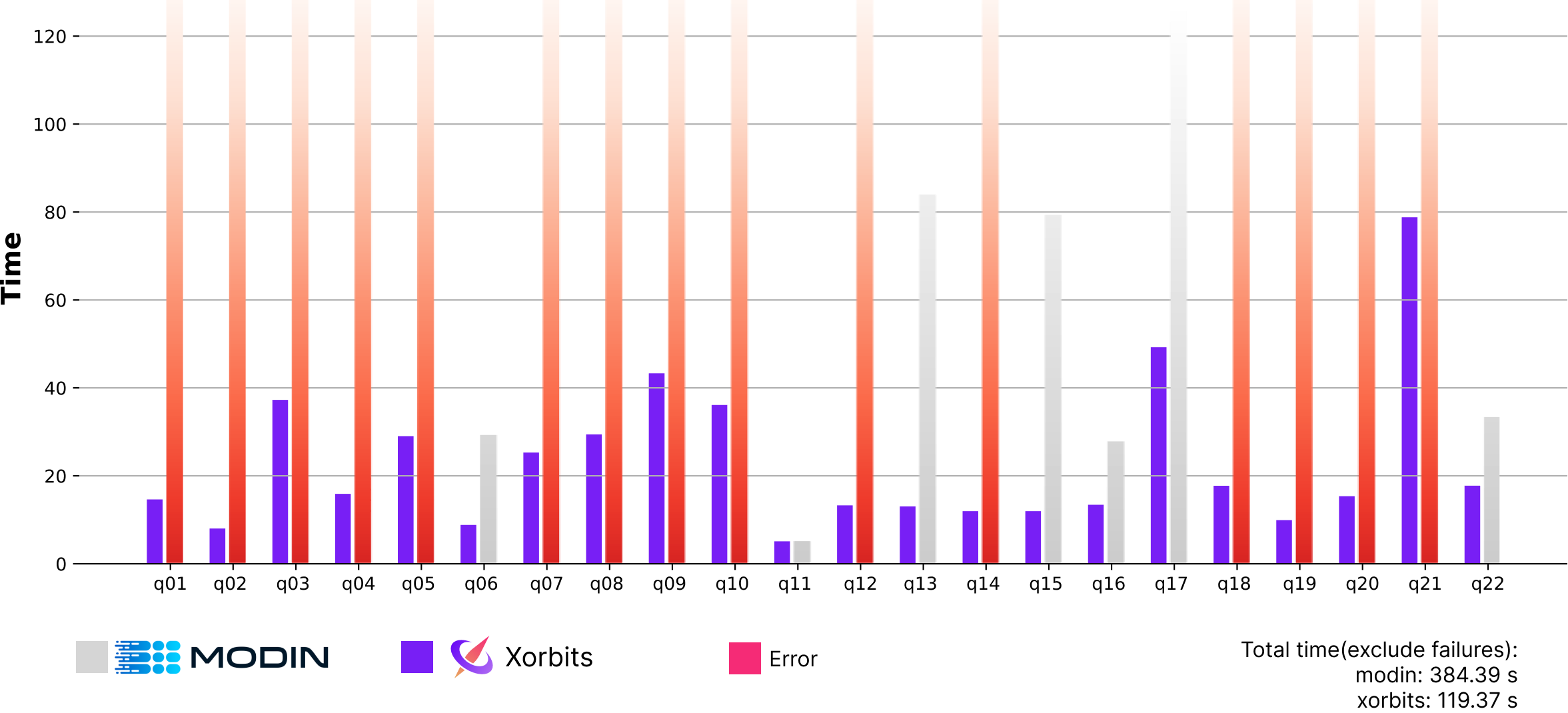
TPC-H SF100: Xorbits vs. Modin
Although Modin ran out of memory for most of the queries that involve heavy data shuffles, which made the performance difference less clear, Xorbits was still found to be 3.2 times faster than Modin in the benchmark test.
TPC-H SF1000: Xorbits
For the TPC-H SF 1000 benchmark, the cluster consisted of an r6i.large instance as the supervisor, and 16 r6i.8xlarge instances as workers.

TPC-H SF1000: Xorbits
In the TPC-H SF 1000 benchmark, Xorbits was able to successfully run all queries, but Dask, Pandas API on Spark, and Modin failed on most of the queries, making it difficult to compare performance differences. We plan to re-run the benchmark at a later time.
Don’t hesitate, try out Xorbits
We encourage you to give Xorbits a try and experience its performance, scalability and ease of use for yourself.
In conclusion, Xorbits is a scalable Python data science framework that aims to scale the entire Python data science world, including numpy, pandas, scikit-learn and many other libraries. It can leverage multi cores or GPUs to accelerate computation on a single machine, or scale out up to thousands of machines to support processing terabytes of data. In our benchmark test, Xorbits is the fastest framework among the most popular distributed data science frameworks.
You can try out Xorbits by installing it via pip by running pip install xorbits. We hope you enjoy using it and we would appreciate your feedback.
Materials
- Github: https://github.com/xprobe-inc/xorbits
- Official site: https://xorbits.io
- Doc: https://doc.xorbits.io